
The DevOps Data Platform
Get fast, compliant data for testing application releases, modernization, cloud adoption, and AI/ML programs—all driven by APIs.
key offerings
use case
technology
industry
The DevOps Data Platform
Get fast, compliant data for testing application releases, modernization, cloud adoption, and AI/ML programs—all driven by APIs.
key offerings
use case
technology
industry
support
OpenZFS: Reducing ARC Lock Contention
tl;dr; Cached random read performance of 8K blocks was improved by 225% by reducing internal lock contention within the OpenZFS ARC on illumos.
Share
tl;dr; Cached random read performance of 8K blocks was improved by 225% by reducing internal lock contention within the OpenZFS ARC on illumos.
Introduction
Real World Problems with the ARC
Performance: Before
Remove the Lists?
Solution: Use More Locks!
Performance: After
Commit Details
Appendix
1. Introduction
Locks are a pain. Even worse, is a single lock serializing all of the page cache accesses for a filesystem. While that's not quite the situation the OpenZFS ARC was in earlier this year, it was pretty close. For those unfamiliar, the OpenZFS file system is built atop its very own page cache based on the paper by Nimrod Megiddo and Dharmendra S. Modha, "ARC: A Self-Tuning, Low Overhead Replacement Cache". While the paper provides a very good basis from which actual code can be written to implement its concepts, there's a number of real world problems it fails to address. For this article, we'll be looking at one of these problems: concurrency.
2. Real World Problems with the ARC
The paper describes a global data structure from which all page accesses are performed; the problem is, it doesn't describe a mechanism to do this safely in a highly concurrent environment. Since any modern file system obviously needs to support multi-threaded concurrent operations, locks had to be added to protect the global data used to manage and implement the ARC. How might one do this? One way is to is to wrap all operations modifying the global structures with a single mutually exclusive lock. This satisfies the requirement that all accesses are safe to perform concurrently from many threads, while also be fairly simple to understand and implement. To my surprise, this is how the OpenZFS ARC was structured for nearly the past decade
3. Performance: Before
As one might expect, the main drawback with this simplistic approach is performance. While safe, on systems with many CPUs, this approach causes terrible lock contention for multi-threaded cached workloads. To highlight this performance issue, I used FIO to perform a cached random read workload using 32 threads. Each thread would use its own unique file, reading 8K blocks at random 8K aligned offsets from its file [Appendix 1]. The aggregate bandwidth was measured while varying the number of virtual CPUs allocated to the virtual machine, and the results are as follows:

See [Appendix 2] for more detailed performance metrics As one can see, the performance scales terribly when increasing the number of CPUs in the system. Not only does performance fail to increase with more CPUs, it actually gets much worse with more CPUs! Clearly this is a bad situation to be in; especially so, with large CPU count systems becoming increasingly more common. Looking at a snippet of lockstat profiling data, it's clear which locks are to blame (the following was taken from a run on a system with 32 CPUs):

The two locks causing the bottleneck are used to protect the ARC's internal lists. These lists contain all ARC buffers residing in the cache that aren't actively used by consumers of the ARC (i.e. buffers with a reference count of zero). Every time a buffer is added or removed from one of these lists, the list's lock must be held. This means the lists' lock must be acquired for all of the following operations: a read from disk, an ARC cache hit, when evicting a buffer, when dirtying a buffer, when all references to a buffer are released by consumers, etc.
4. Remove the Lists?
Before I dive into the solution that was taken, I should make it clear why the lists are needed in the first place. These lists allow for iterating over the buffers from the least recently accessed buffer to the most recently accessed buffer, or vice versa. The ability to do this iteration is critical to implementing the ARC as described by the paper. It allows for the least recently accessed buffer to be selected in constant-time during the eviction process [Appendix 3].
5. Solution: Use More Locks!
To alleviate the issue, we really needed a way to perform this iteration without causing so much locking overhead to the performance critical code paths (e.g. during a ARC cache hit). The solution we decided on is to split each of the ARC's internal lists into a variable number of sublists, each sublist having its own lock and maintaining a time ordering within itself (i.e. the buffers in each sublist are ordered based on access time, but there's no ordering of buffers between the different sublists).
Thus, a new data structure was created to encapsulate these semantics, a "multilist" [Appendix 4]. On the surface this seems like a pretty trivial change, but there's a key aspect that make it more complex to implement than one might expect. Due to the sublists not maintaining a strict ordering between each other, selecting the least (or most) recently accessed buffer is no longer a constant-time operation.
In general, it becomes a linear-time operation as each sublist must be iterated, comparing the elements in each sublists with each other. A linear-time lookup of the least recently accessed buffer is insufficient, so a clever domain-specific workaround was used to allow for this lookup to maintain its constant-time complexity. Rather than selecting the absolute least recently accessed buffer during eviction, a buffer that is "old enough" is selected instead; this selection happening in constant-time. We do this by evenly inserting buffers into each sublist, and then during eviction, a randomly selected sublist is chosen.
This sublist's least recently accessed buffer is selected and evicted. This process will select a buffer that's "old enough" based on the fact that buffers are evenly inserted into each of the sublists, so each sublist's least recently accessed buffer will have an access time proportional to all other sublists' least recently accessed buffer [Appendix 5].
6. Performance: After
As with any performance related change, empirical results are necessary to give the change any sort of credibility. So, the workload that was previously used to exemplify the problem [Appendix 1], was used again to ensure the expected performance gains were achieved. The following table contains aggregate bandwidth numbers with the fix in place ("Bandwidth After" column), as well as the aggregate bandwidth numbers without the fix ("Bandwidth Before" column, the same results previously shown):
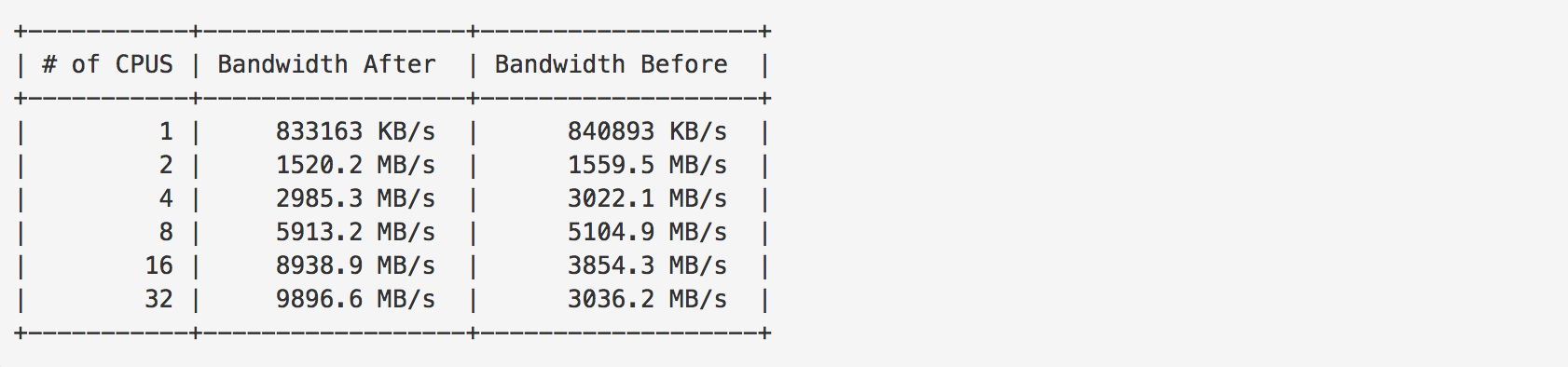
As expected, performance scales much better as more CPUs are added to the system, and the overall performance saw a 225% improvement when using 32 CPUs (the largest CPU count I had available to test). Also, the performance difference when using a small number of CPUs was negligible. Lockstat was used again, and contention is clearly much less than before (as before, this snippet was taken from a run on a system with 32 CPUs):

Success!
7. Commit Details
For those interested, this fix was committed to illumos on January 12th, 2015 via this commit:
It's also in the process of being ported and merged into FreeBSD and OpenZFS on Linux (at least, it was at the time of this writing).
8. Appendix
The FIO script used to run the performance benchmarks is below. Keep in mind, this script was run a number of times prior to gathering the performance data, as I was specifically targeting a fully cached workload and needed to ensure the files were cached in the ARC.

In addition to the run used to gather the aggregate bandwidth numbers, the FIO script was run a couple more times to gather more useful debugging and performance metrics. Specifically, it was run with lockstat profiling enabled, which was used to pinpoint the lock(s) causing the poor scaling. As well as another iteration with flame graph profiling enabled to pinpoint the specific functions of interest (additionally to provide corroborating evidence to back up the lockstat data). Unfortunately, it looks like I can't upload SVG or TAR files; so if anybody is interested in the full lockstat output or the flamegraphs, drop me an email and we can work something out (probably just email the TAR archive directly as it's only 227K compressed).
The lists can also be iterated starting from the most recently accessed buffer to the least recently accessed buffer too. This iteration direction is used when populating the L2ARC device prior to the cache being "warmed up".
This concept is not original to me, as FreeBSD has included a similar fix to the ARC in their platform for some time. FreeBSD's usage of this concept actually gave me confidence that it would work out in practice, prior to actually having a working solution.
I realize "old enough" is vague, but essentially what we're doing here is using a heuristic to determine what buffer would be the best candidate to be evicted from the cache. So, we're modifying the previous heuristic from always selecting the absolutely oldest buffer, to being a randomly selected buffer out of a group of "old" buffers. The group of old buffers being composed of the tails of all the sublists.